Avoid being deceived by data
Data visualizations tend to be a primary source of confusion and misrepresentations of reality. Oftentimes, it’s simply inept, and you end up looking at convoluted charts that mean nothing to anyone except the analyst. Other times, however, misleading graphs can be purposefully propelled to fulfill ulterior motives. Some of the worst offenders include:
Pie Charts are hard to read, can easily distort proportions, and are almost universally derided by analysts. Portions of the pie can be made to appear the same size, even though one is actually much smaller in terms of quantity.
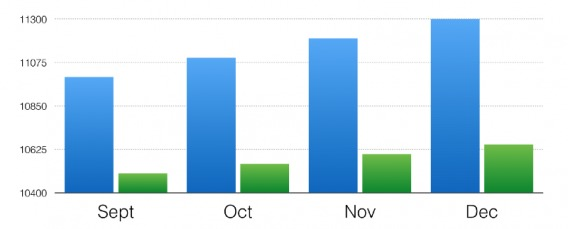
Cropped Axes can make the difference between two data sets look much larger than it actually is. For example, the y axis for the first chart below starts at 10,400, while in the second chart it starts at zero. Huge difference, right?